Action-GPT:
Leveraging Large-scale Language Models for Improved and
Generalized Action Generation
Sai Shashank Kalakonda Shubh Maheshwari Ravi Kiran Sarvadevabhatla
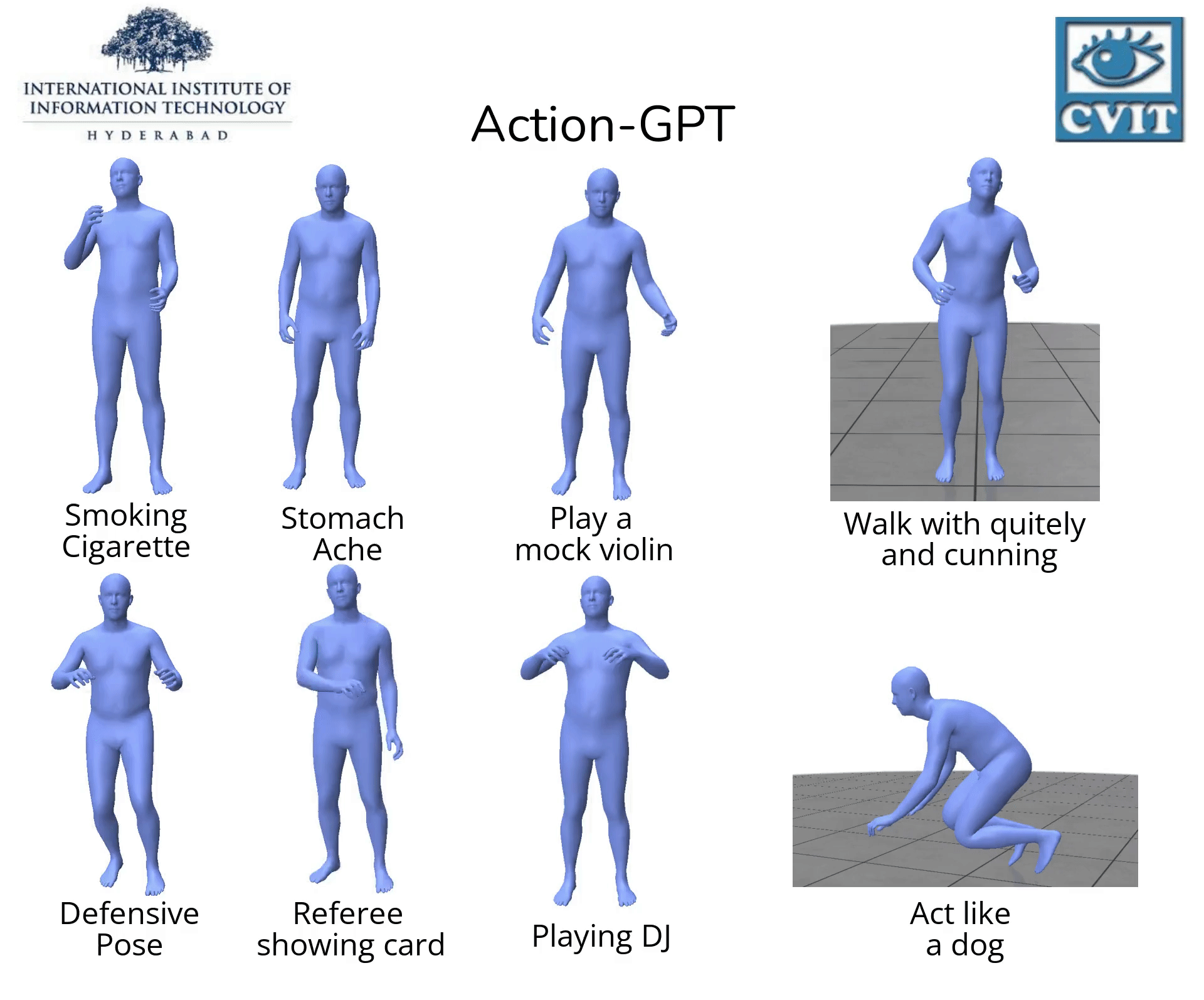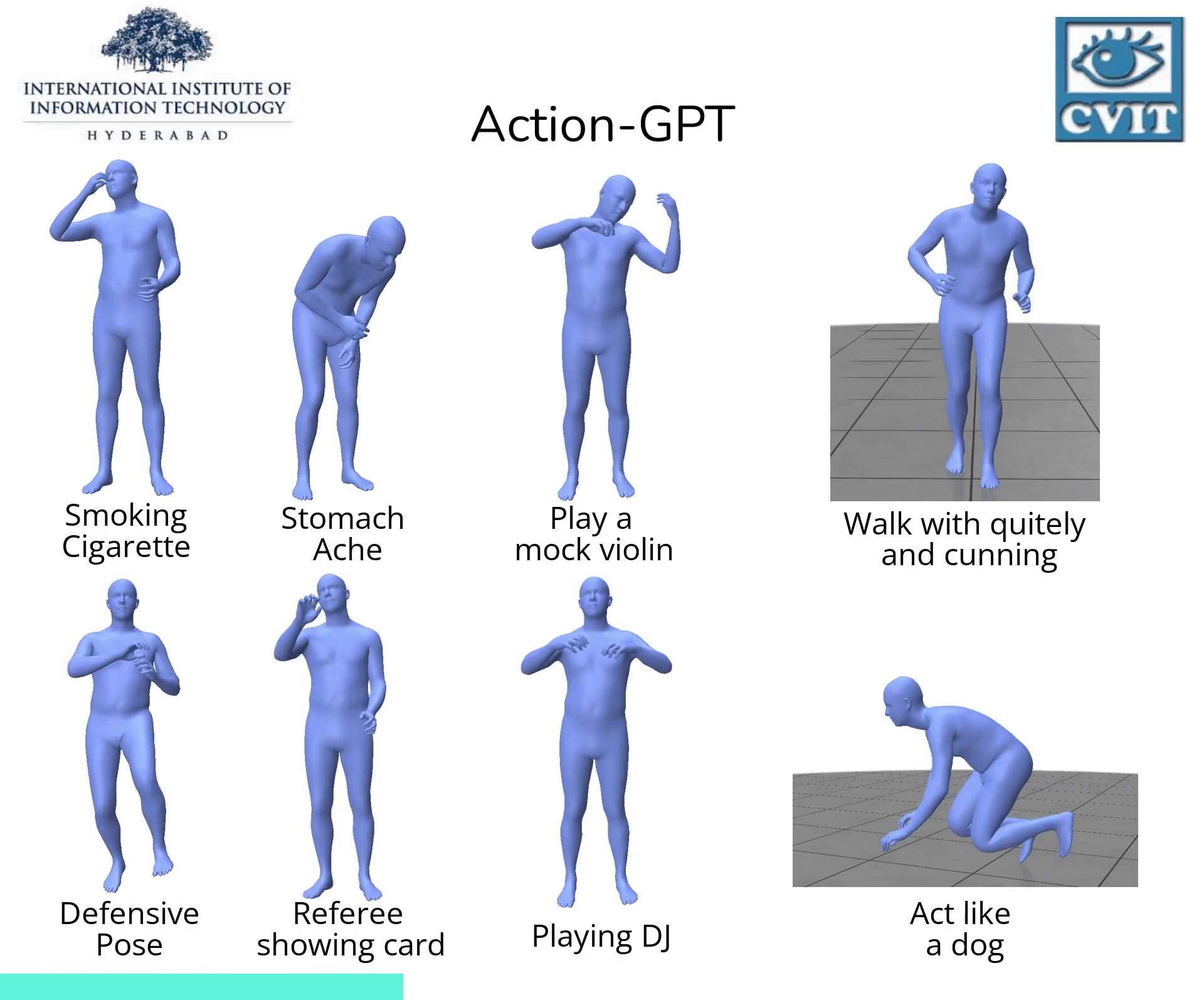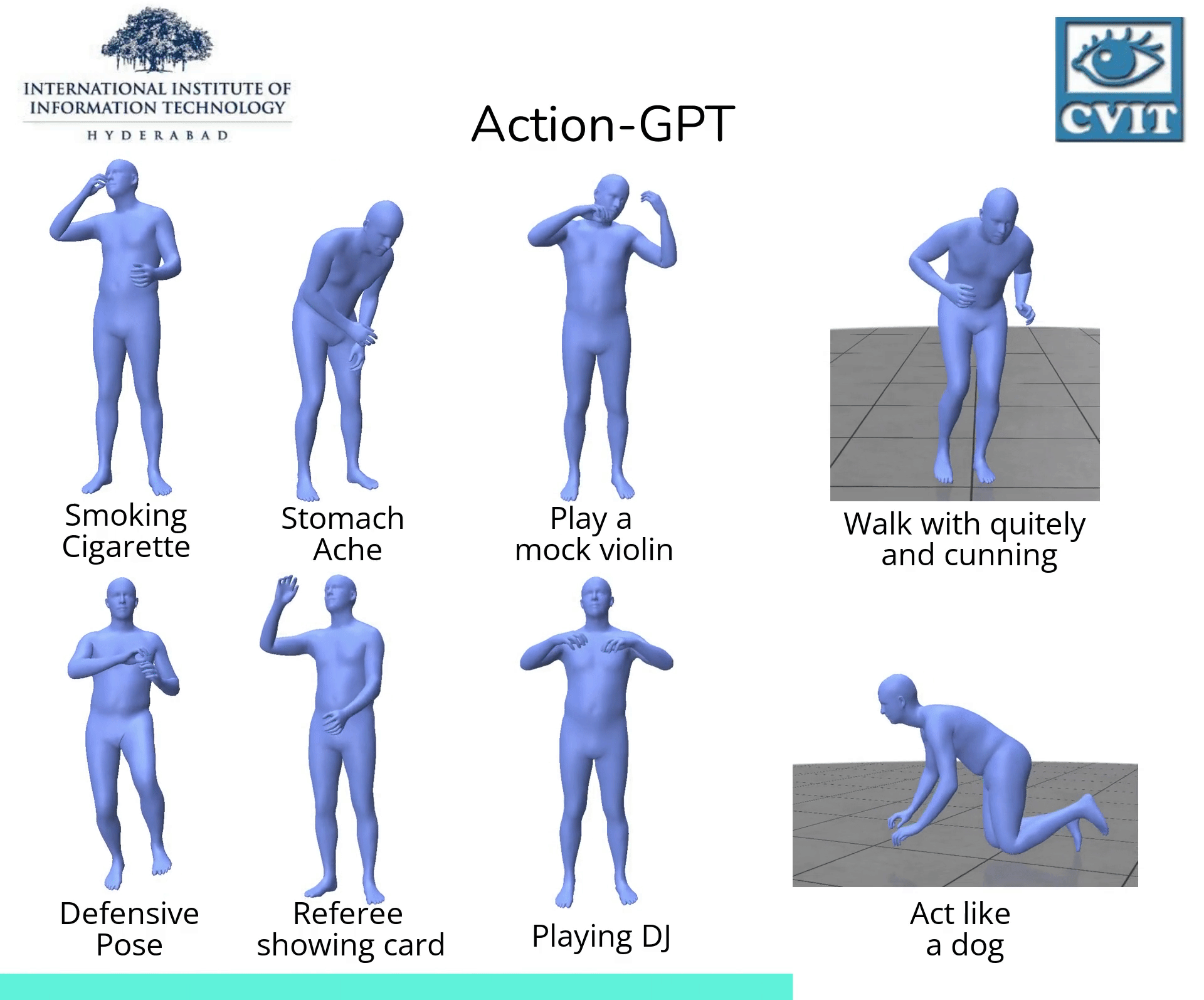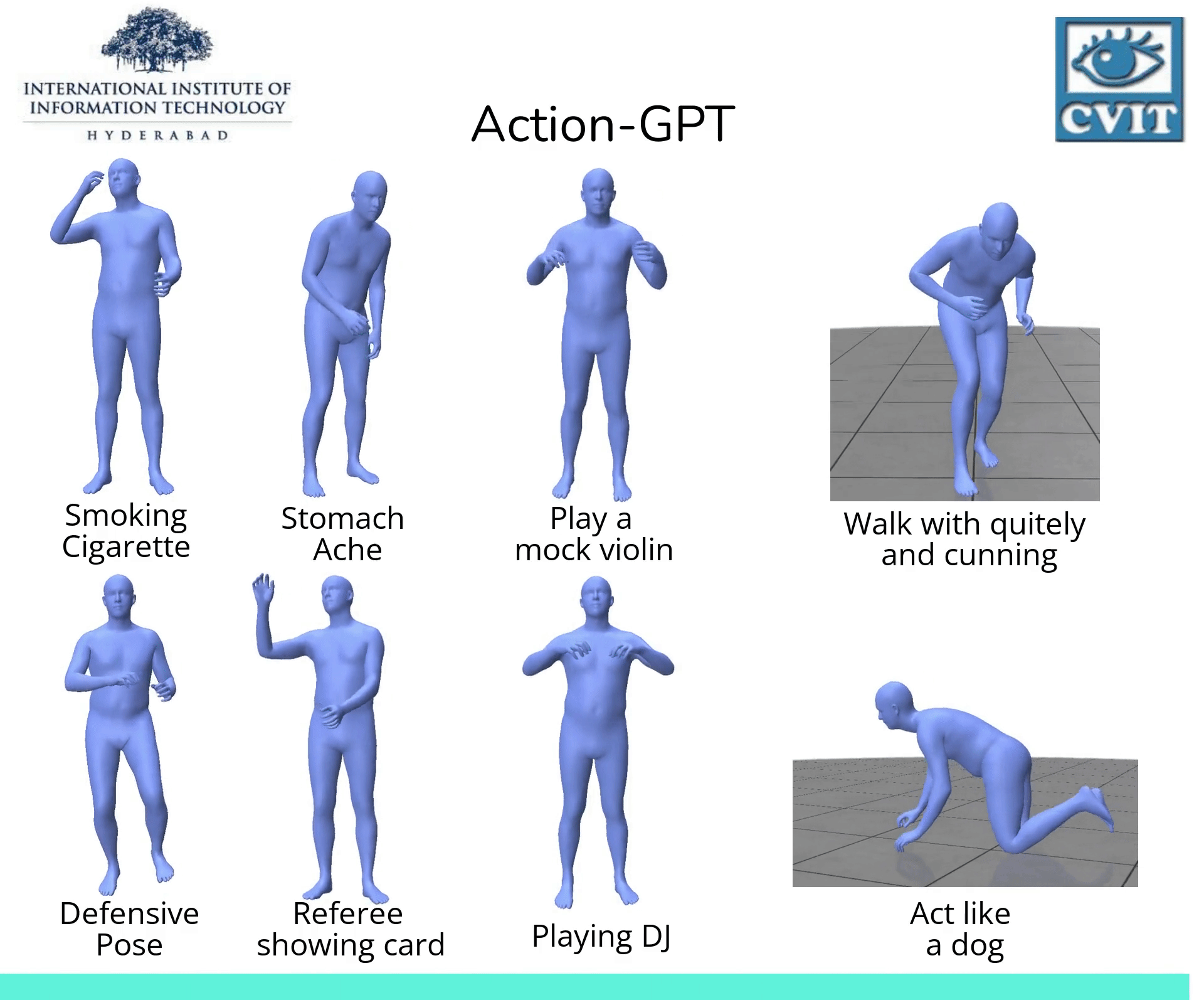
Abstract
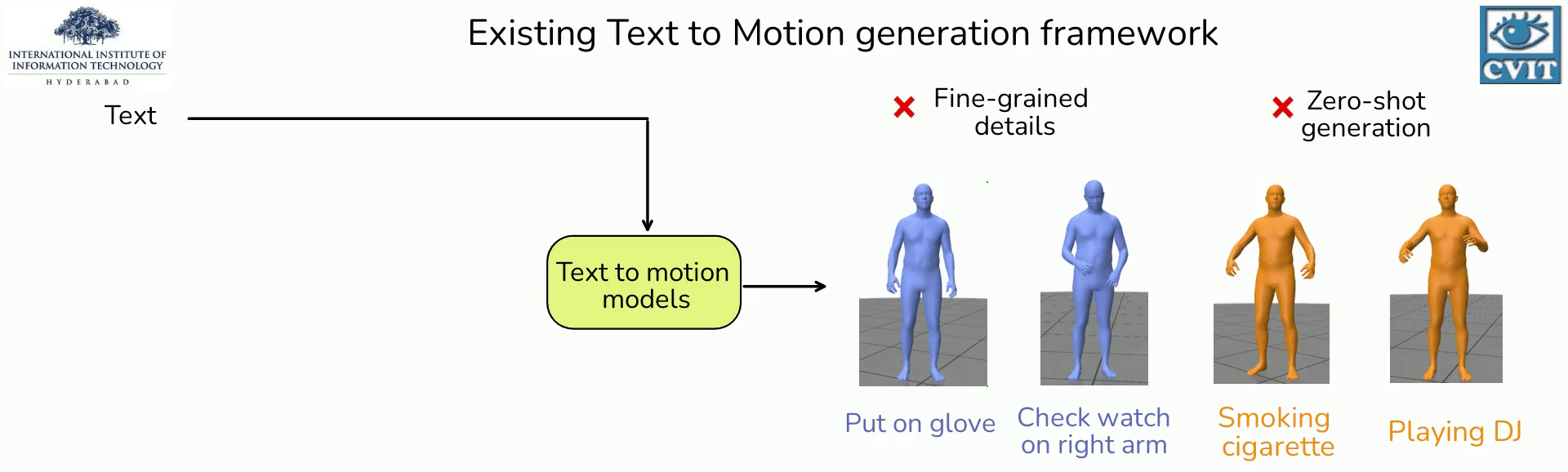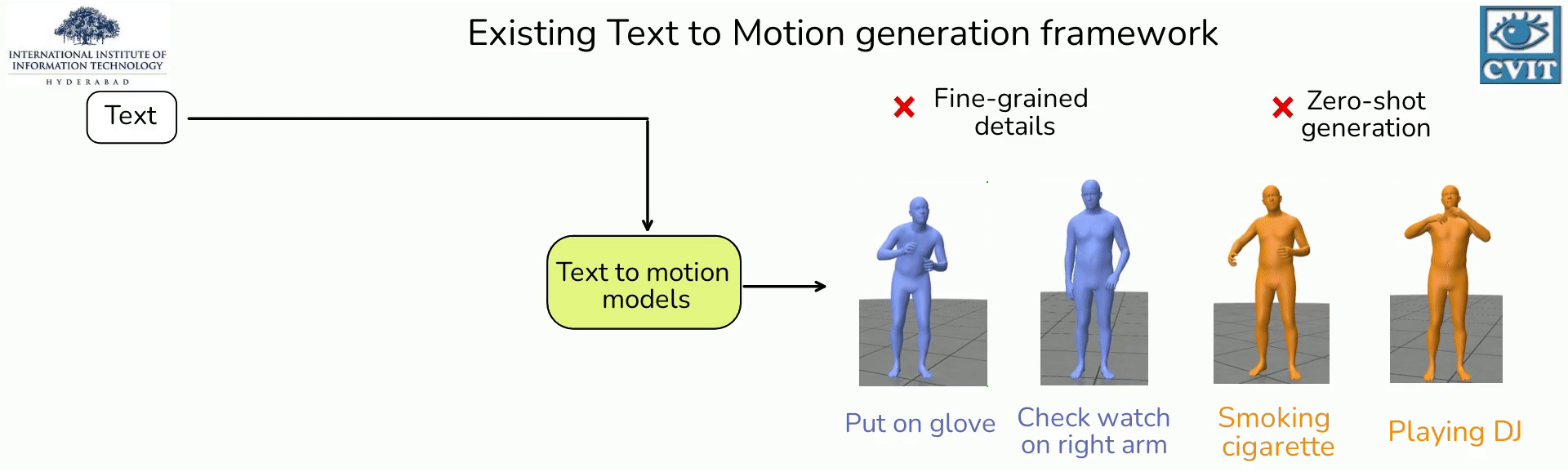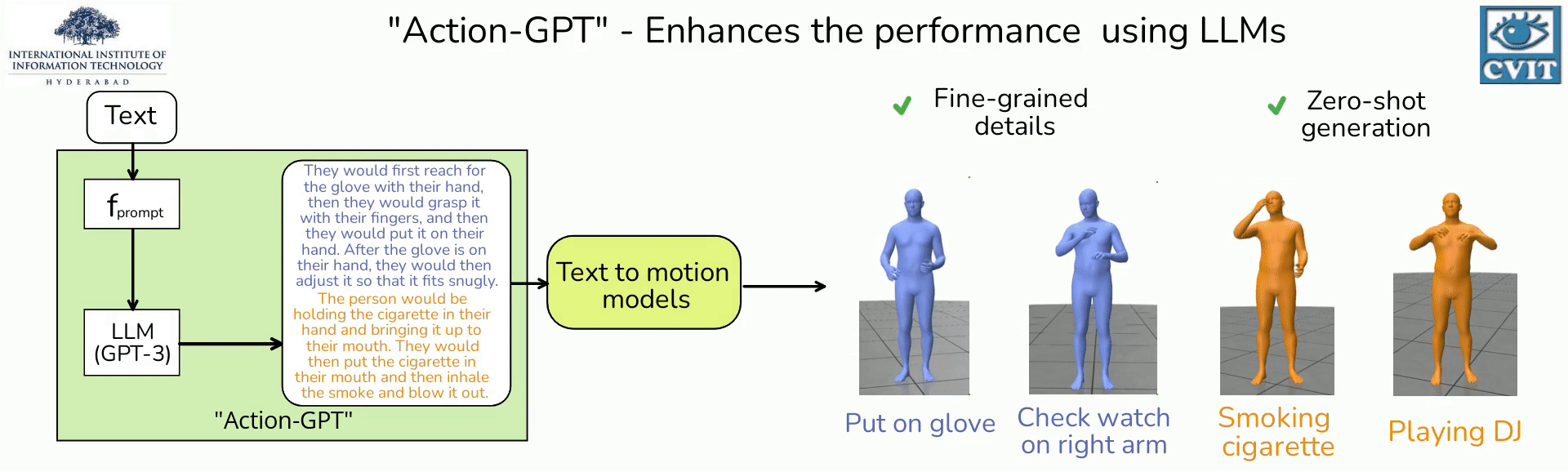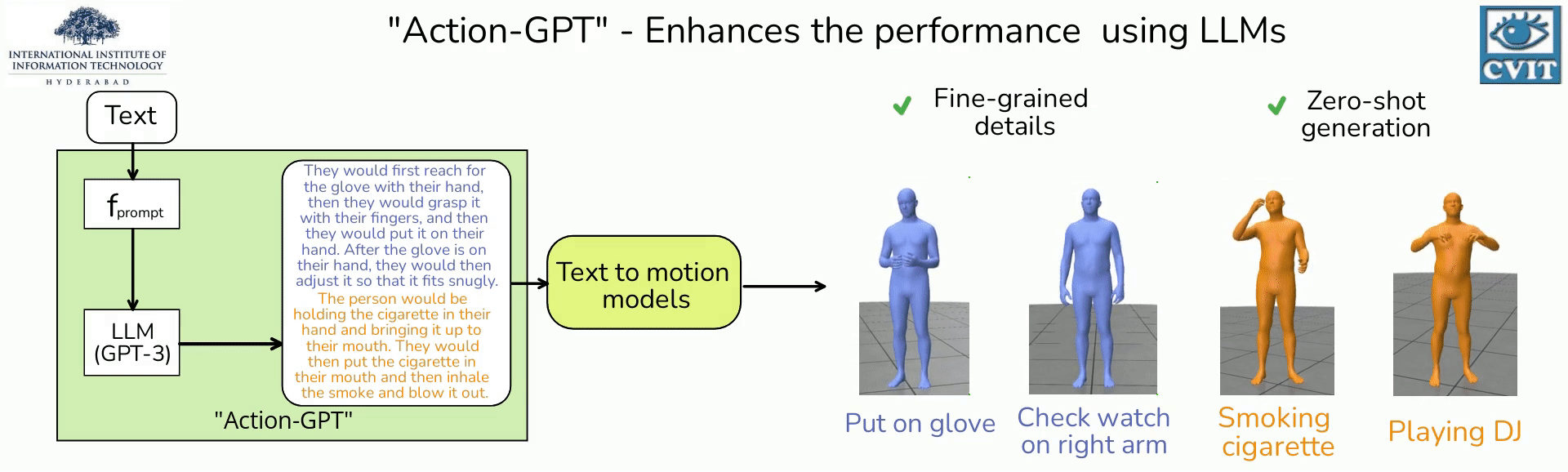
We introduce Action-GPT,
- A plug and play framework for incorporating Large Language Models (LLMs) into text-based action generation models
- By carefully crafting prompts for LLMs, we generate richer and fine-grained descriptions of the action.
- We show that utilizing these detailed descriptions instead of the original action phrases leads to better alignment of text and motion spaces.
- Our experiments show qualitative and quantitative improvement in the quality of synthesized motions produced by recent text-to-motion models.
- Code, pretrained models and sample videos will be made available.
Motivation
Overview

Comparisons
Citation
@InProceedings{Action-GPT,
title={Action-GPT: Leveraging Large-scale Language Models for Improved and Generalized Action Generation},
author={Kalakonda, Sai Shashank and Maheshwari, Shubh and Sarvadevabhatla, Ravi Kiran},
booktitle={arXiv preprint https://arxiv.org/abs/2211.15603},
year={2022}
}